



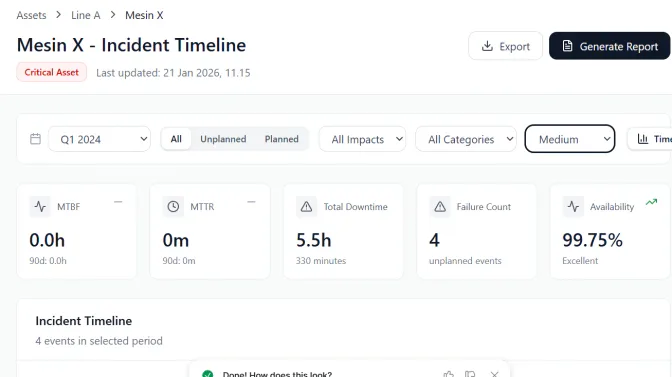
Mean Time Between Failures (MTBF) sering jadi angka yang paling cepat menunjukkan “kondisi kesehatan” sebuah mesin atau sistem. Dalam satu metrik, tim bisa melihat rata-rata jarak waktu operasi antara satu failure dan failure berikutnya pada aset yang bisa diperbaiki.
Cara menghitungnya cukup sederhana, yaitu waktu operasi efektif dibagi jumlah failure pada periode yang sama. Setelah itu, MTBF biasanya dibaca sebagai tren dan dipasangkan dengan Mean Time to Repair (MTTR) agar keputusan pemeliharaan lebih tepat dan konsisten.
Key Takeaways
|
MTBF Mengukur Apa?
Mean Time Between Failures (MTBF) menunjukkan rata-rata jarak waktu antara satu kejadian gagal dan kejadian gagal berikutnya saat alat benar-benar dipakai. MTBF menjawab pertanyaan, “dalam pola operasional normal, rata-rata berapa jam alat bisa jalan sebelum gangguan yang menghambat kerja muncul lagi?”
Katakanlah sebuah mesin berjalan 2.000 jam dalam 3 bulan dan mengalami 10 kali gangguan yang menghentikan proses. Mean Time Between Failures (MTBF) = 2.000 / 10 = 200 jam.
Artinya, tiap sekitar 200 jam operasi, mesin tersebut cenderung mengalami satu gangguan yang perlu ditangani.
Angka ini cocok dipakai untuk membaca pola frekuensi gangguan. Jika Mean Time Between Failures (MTBF) bulan ini 200 jam lalu bulan depan turun jadi 120 jam, berarti gangguan terjadi lebih sering dan ada yang perlu ditelusuri.
Sedangkan ketika Mean Time Between Failures (MTBF) naik, itu berarti sinyal gangguan makin jarang. Lalu tim bisa mengecek praktik pemeliharaan mana yang paling berpengaruh.
Definisi Failure Dan Scope Sistem
Mean Time Between Failures (MTBF) bisa menyesatkan kalau perusahaan belum sepakat tentang dua hal. Pertama, failure itu apa dan kedua, sistem yang dihitung itu yang mana.
Definisi failure
Pilih definisi yang bisa dipakai semua tim secara konsisten. Contoh yang umum dipakai merupakan:
Stop produksi: mesin berhenti dan output tidak bisa jalan.
- Gangguan wajib tindakan: perlu reset, restart, ganti part, atau panggil teknisi supaya normal lagi.
- Turun performa melewati batas: misalnya reject rate melewati ambang, kecepatan turun jauh, atau suhu/getaran melewati limit sehingga proses harus dihentikan.
Untuk IT, failure bisa disepakati sebagai:
- Service down (aplikasi tidak bisa dipakai), atau
- Insiden besar (misalnya transaksi gagal massal), atau
- Pelanggaran SLA (latency di atas batas selama durasi tertentu).
Definisinya harus cukup jelas sampai orang yang berbeda tetap mencatat kejadian yang sama dengan cara yang sama.
Scope sistem
Tentukan batas yang dihitung sejak awal, misalnya:
- MTBF Mesin Filling A, atau
- MTBF Line Produksi Minuman, atau
- MTBF Sistem Order-to-Delivery.
Kalau scope terlalu lebar, satu failure kecil di satu komponen bisa dianggap failure sistem besar dan membuat angkanya sulit ditafsirkan.
Biasanya, langkah paling cepat adalah mulai dari aset kritis. Alat yang paling sering menghentikan kerja atau yang downtime-nya paling mahal.
Checklist data minimal
Setiap kejadian failure dan MTBF idealnya punya:
- Nama aset + lokasi/line
- Waktu mulai gangguan
- Waktu kembali normal
- Kode gangguan singkat (misal belt putus, sensor error, overheat)
- Catatan singkat tindakan (reset/ganti part/kalibrasi)
Rumus MTBF Dan Waktu Operasi Efektif
Rumus MTBF yaitu:
| Mean Time Between Failures (MTBF) | = | Total Waktu Operasi Efektif ÷ Jumlah Failure |
Gunakan waktu operasi efektif (jam alat benar-benar berjalan), bukan jam kalender.
Waktu operasi efektif berarti jam alat benar-benar berjalan untuk menghasilkan output, sesuai scope yang sudah ditetapkan. Kalau perusahaan memakai jam kalender tanpa memilah, angka MTBF bisa jadi terlalu tinggi atau terlalu rendah.
Agar gampang dipakai, tim operasional biasanya membedakan tiga jenis waktu:
- Waktu operasi efektif: alat berjalan dan dipakai produksi/layanan.
- Planned downtime: berhenti karena jadwal (maintenance terencana, libur produksi, setup terjadwal).
- Unplanned downtime: berhenti karena failure (yang Anda hitung sebagai jumlah failure dan juga memengaruhi waktu operasi efektif).
Cara menentukan waktu operasi efektif (praktis):
- Tentukan periode (misalnya 1 bulan).
- Ambil total jam jadwal operasi pada periode itu (misalnya 8 jam/hari × 26 hari kerja).
- Kurangi planned downtime yang memang sudah dijadwalkan (misalnya shutdown terencana 10 jam).
- Hasilnya menjadi waktu operasi efektif yang dipakai dalam rumus MTBF.
Supaya konsisten, tuliskan aturan sederhana di awal. Apakah waktu operasi efektif dihitung dari jadwal operasi atau jam mesin benar-benar running dari counter/sensor. Kalau punya hour meter/PLC log, biasanya hasilnya lebih akurat.
Contoh Hitung MTBF Di Lapangan
Berikut contoh menghitung MTBF yang umum terjadi di operasional mesin produksi sehari-hari.
Mesin Produksi Dengan Planned Downtime
Sebuah mesin berjalan 8 jam per hari, 26 hari kerja dalam sebulan.
- Jadwal operasi = 8 × 26 = 208 jam
- Ada planned downtime untuk preventive maintenance terjadwal = 8 jam
- Maka waktu operasi efektif = 208 − 8 = 200 jam
- Dalam bulan itu terjadi 5 failure (sesuai definisi: mesin stop dan butuh tindakan teknisi)
Mean Time Between Failures (MTBF) = 200 ÷ 5 = 40 jam
Artinya, rata-rata setiap 40 jam operasi efektif, mesin mengalami satu gangguan yang menghambat produksi.
Sistem IT Dengan Maintenance Terencana
Sebuah aplikasi internal dipakai 24/7 dalam 30 hari.
- Total jam kalender = 30 × 24 = 720 jam
- Ada maintenance terjadwal (planned downtime) = 6 jam
- Waktu operasi efektif = 720 − 6 = 714 jam
- Dalam periode tersebut terjadi 3 incident yang memenuhi definisi failure (service down dan user tidak bisa transaksi)
Mean Time Between Failures (MTBF) = 714 ÷ 3 = 238 jam
Artinya, rata-rata ada satu gangguan besar setiap ±238 jam operasi efektif.
MTBF Vs MTTR Vs MTTF
Banyak tim memakai Mean Time Between Failures (MTBF) untuk menilai keandalan, tetapi kesimpulannya sering meleset karena metrik lain ikut tercampur. Supaya interpretasinya tidak salah arah, bagian ini merangkum perbedaan MTBF, Mean Time to Repair (MTTR), dan Mean Time to Failure (MTTF).
| Metrik | Kepanjangan | Mengukur Apa | Dipakai Saat |
|---|---|---|---|
MTBF |
Mean Time Between Failures | Rata-rata jeda waktu operasi antara satu failure dan failure berikutnya pada sistem repairable. | Saat ingin melihat seberapa sering gangguan terjadi dan memantau tren reliabilitas aset. |
MTTR |
Mean Time to Repair | Rata-rata waktu yang dibutuhkan untuk memulihkan sistem hingga normal setelah failure. | Saat ingin mengurangi durasi downtime dan mempercepat respons perbaikan. |
MTTF |
Mean Time to Failure | Rata-rata waktu sampai komponen gagal total pada item non-repairable (umumnya diganti). | Saat ingin menetapkan umur pakai komponen yang langsung diganti, termasuk rencana stok pengganti. |
Cara Pakai MTBF Tanpa Salah Baca
Anda akan melihat cara membaca MTBF sebagai pola di mana mesin Anda mengalami kegagalan dan apa yang harus dilakukan.
- Gunakan MTBF sebagai tren, bukan angka sekali lihat.
Bandingkan Mean Time Between Failures (MTBF) aset yang sama per minggu/bulan untuk melihat pola naik-turun yang konsisten. - Selalu kaitkan MTBF ke keputusan yang konkret.
Misalnya: aset mana yang harus diprioritaskan inspeksi, komponen mana yang perlu disiapkan spare part, dan proses mana yang perlu diperketat. - Pasangkan MTBF dengan MTTR.
MTBF yang tinggi tetap bisa menyulitkan operasional jika Mean Time to Repair (MTTR) panjang dan downtime tiap gangguan besar. - Pisahkan planned downtime dari failure sejak awal.
Maintenance terjadwal, libur produksi, dan shutdown terencana sebaiknya dicatat terpisah agar hitungan MTBF tidak bias. - Tetapkan definisi failure yang konsisten untuk semua tim.
Buat aturan yang jelas tentang kejadian apa yang dihitung sebagai failure (stop total, intervensi teknisi, pelanggaran SLA) agar data tidak berubah. - Cek kualitas perbaikan, bukan sekadar cepat pulih.
Jika failure yang sama berulang, MTBF bisa terlihat stabil padahal masalah akar belum selesai; tandai failure berulang dan lakukan analisis akar masalah. - Jangan mengejar angka MTBF dengan mengurangi pencatatan incident.
Kalau targetnya reliabilitas, indikator lapangan yang ikut membaik biasanya downtime total turun, gangguan berulang menurun, dan output lebih stabil.
Kesimpulan
Mean Time Between Failures (MTBF) membantu perusahaan melihat seberapa sering gangguan terjadi dan aset mana yang paling perlu diprioritaskan. Hasilnya akan akurat jika definisi failure konsisten dan waktu operasi efektif dihitung dengan benar.
Agar tidak salah baca, pantau MTBF sebagai tren dan baca berdampingan dengan Mean Time to Repair (MTTR) serta total downtime. Dengan pencatatan yang rapi, keputusan maintenance jadi lebih cepat, terarah, dan berbasis data.









